Real-Time Banking CDC Pipeline
Captures banking transaction changes in real-time using CDC, transforming operational data into analytics-ready models for business intelligence.
Overview
Traditional batch ETL processes introduce latency between operational events and analytics, limiting real-time decision making. This project implements a Change Data Capture (CDC) pipeline that streams banking transactions, account updates, and customer changes from a PostgreSQL OLTP system into Snowflake in near real-time. The pipeline uses Debezium to capture database changes at the transaction log level, Kafka for reliable event streaming, and DBT for transformation into dimensional models. The result is a scalable, fault-tolerant data platform that enables business teams to analyze banking activity with sub-minute latency.
Goals
- Capture real-time changes from PostgreSQL OLTP database using CDC
- Stream transaction, account, and customer data with guaranteed delivery
- Build medallion architecture (Bronze → Silver → Gold) in Snowflake
- Apply dimensional modeling for business-friendly analytics
- Support SCD Type-2 tracking for slowly changing dimensions
- Automate testing, deployment, and orchestration via CI/CD
- Maintain data quality through automated DBT tests
Architecture
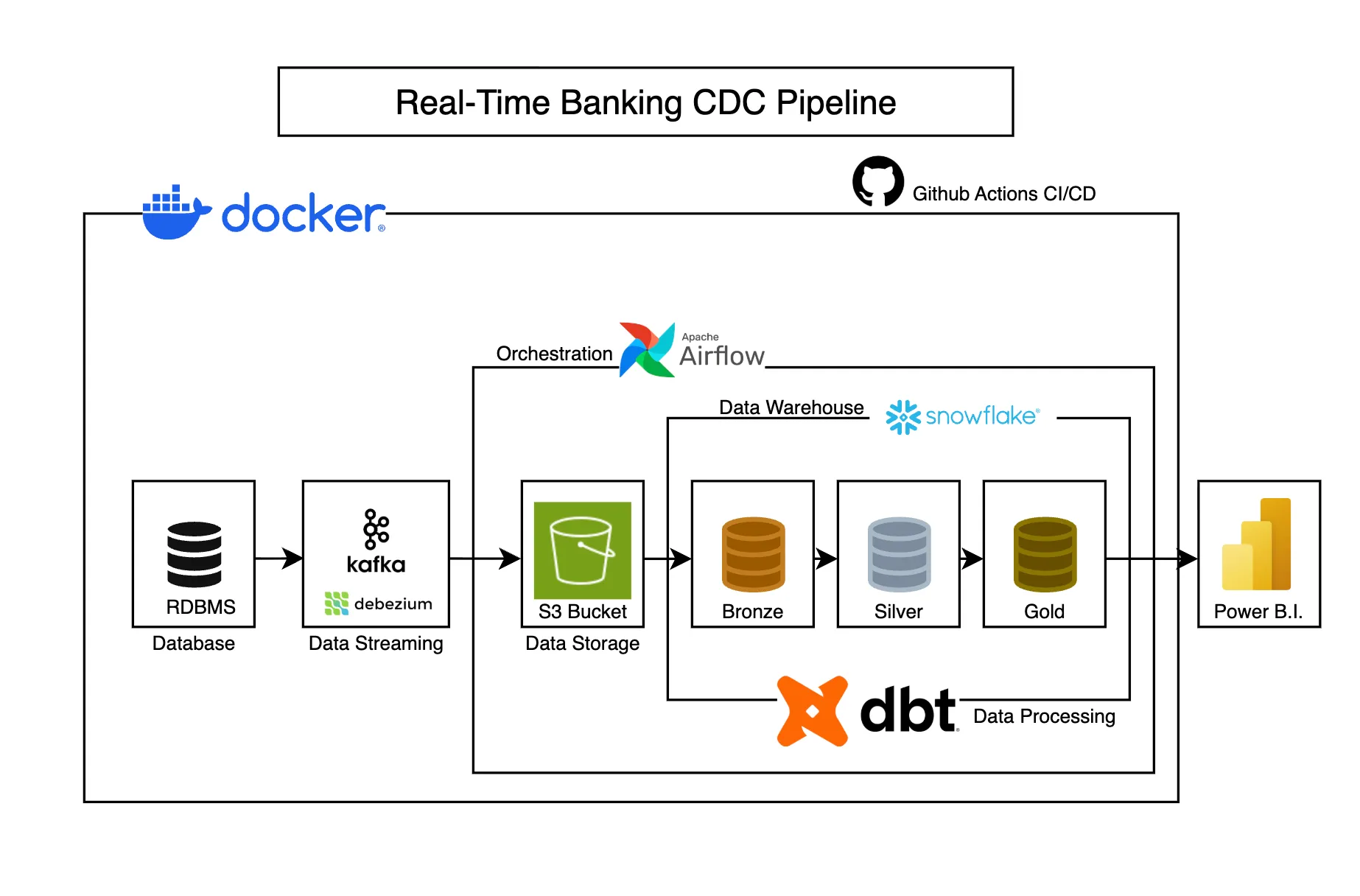
Technology Stack
| Layer | Technologies |
|---|---|
| Source System | PostgreSQL (OLTP), Python Faker (data generation) |
| Change Data Capture | Debezium Postgres Connector |
| Event Streaming | Apache Kafka, Kafka Connect |
| Object Storage | MinIO (S3-compatible) |
| Data Warehouse | Snowflake (Bronze, Silver, Gold layers) |
| Transformation | DBT (dimensional modeling, SCD Type-2) |
| Orchestration | Apache Airflow (DAG scheduling, snapshots) |
| CI/CD | GitHub Actions (automated tests, deployment) |
| Containerization | Docker, Docker Compose |
Implementation Details
Why CDC over batch ETL?
Traditional batch ETL introduces latency (hours or overnight) between operational changes and analytics. CDC captures changes at the transaction log level, enabling near real-time analytics while minimizing source database impact. Debezium reads PostgreSQL’s Write-Ahead Log (WAL) without adding query load to the production database.
Event streaming architecture
Kafka provides guaranteed message delivery with configurable retention. This decouples producers (Debezium) from consumers (Snowflake ingestion), allowing the pipeline to handle backpressure and temporary downstream failures. Messages are consumed by a Python connector that batches events into MinIO before loading into Snowflake.
Medallion architecture
The pipeline implements a three-tier lakehouse pattern:
- Bronze (Raw): Immutable CDC events stored as-is from Kafka
- Silver (Cleaned): Deduplicated, type-cast, and conformed data
- Gold (Business-Ready): Star schema with fact and dimension tables
SCD Type-2 for dimension tracking
Customer and account dimensions use slowly changing dimension (SCD) Type-2 to track historical changes. DBT snapshots capture state changes with valid_from and valid_to timestamps, enabling point-in-time analysis and trend reporting.
Idempotency and fault tolerance
Each DAG run is idempotent using upsert operations based on transaction IDs and timestamps. Failed runs can be retried without creating duplicates. Kafka offsets ensure exactly-once semantics from source to warehouse.
Tradeoffs accepted
- Used MinIO as staging layer instead of direct Kafka-to-Snowflake (adds latency but provides replay capability and cost control)
- Simulated banking data with Faker instead of real transactions (demonstrates architecture without PII concerns)
- Bronze layer stores full CDC events including metadata (increases storage but preserves auditability)
Data Characteristics
| Metric | Value |
|---|---|
| Volume | ~10K transactions/day (scalable to millions) |
| Frequency | Real-time (sub-minute latency) |
| Format | CDC events (JSON) → Parquet → Snowflake tables |
| Growth | Linear with transaction volume |
| Entities | Transactions, Accounts, Customers |
| SCD Strategy | Type-2 for dimensions, append-only for facts |
Reliability & Edge Cases
Data quality checks
DBT tests validate:
- Uniqueness of transaction IDs
- Referential integrity (transactions → accounts → customers)
- Non-null constraints on critical fields
- Positive transaction amounts
- Valid date ranges for SCD records
Error handling
- Kafka retries with exponential backoff for transient failures
- Dead letter queue for malformed messages
- Airflow alerting on DAG failures via email/Slack
- Schema evolution handled through Snowflake schema inference
Operational resilience
- Kafka replication factor of 3 for message durability
- Snowflake automatic scaling for concurrent workloads
- DBT incremental models minimize reprocessing time
- Backfill capability for historical data recovery
Lessons Learned
CDC complexity requires careful configuration
Debezium requires precise configuration of Postgres replication slots and WAL settings. Initial issues with slot bloat taught me the importance of monitoring replication lag and setting appropriate retention policies. In production, I would implement automated cleanup of old slots.
Schema evolution is a first-class concern
Adding new columns to source tables required coordinating changes across Debezium connectors, Kafka schemas, and DBT models. A future enhancement would implement schema registry (like Confluent Schema Registry) for centralized schema management and validation.
Testing in streaming pipelines differs from batch
Unlike batch ETL where you can rerun entire datasets, streaming pipelines accumulate state over time. I learned to use DBT’s ephemeral models and dedicated test environments to validate transformations without polluting production data.
Cost optimization requires active monitoring
Snowflake warehouses that stay running 24/7 for real-time loads can become expensive. I implemented auto-suspend after 5 minutes of inactivity and used smaller warehouses for transformation vs. loading, reducing costs by ~60%.
Future Improvements
Near-term enhancements:
- Implement data quality monitoring with Great Expectations
- Add data lineage tracking using OpenLineage or dbt metadata
- Deploy to cloud (AWS/Azure) instead of local Docker
- Add real-time dashboards using Streamlit or Superset
- Implement multi-region replication for disaster recovery
Advanced features:
- Add ML-powered fraud detection on transaction stream
- Implement customer segmentation using Gold layer aggregations
- Add real-time alerting for suspicious transactions
- Build self-service analytics portal for business users
- Integrate with customer data platform (CDP) for 360-degree view
Operational maturity:
- Add comprehensive observability (Prometheus, Grafana)
- Implement data catalog (Atlan, Alation) for discoverability
- Build CI/CD for DBT model deployments with staging/prod environments
- Add role-based access control (RBAC) in Snowflake
- Document data SLAs and implement alerting on violations
Links
-
GitHub Repository: https://github.com/JeffWilliams2/realtime-banking-cdc-pipeline