Kafka vs. Pub/Sub — Choosing a Streaming Backbone for Your Data Platform
A hands-on comparison of Apache Kafka and Google Pub/Sub covering throughput, ordering guarantees, ecosystem, and when to use each.
· projects · 2 minutes
Kafka vs. Pub/Sub — Choosing a Streaming Backbone for Your Data Platform
Both Apache Kafka and Google Pub/Sub solve the same core problem: decoupling data producers from consumers in a streaming architecture. But they differ significantly in operational model, guarantees, and ideal use cases.
Operational Model
Kafka is infrastructure you manage (even on managed services like Confluent Cloud, you’re making decisions about partitions, retention, and cluster sizing). Pub/Sub is fully serverless — Google handles scaling, replication, and storage. You interact with topics and subscriptions; there’s no concept of brokers or partitions to tune.
If you’re on GCP and don’t have a dedicated infrastructure team, Pub/Sub removes significant operational burden.
Ordering and Partitioning
Kafka provides strict ordering within a partition. If event order matters (financial transactions, state machines), you assign a partition key, and all events with that key go to the same partition in order.
Pub/Sub offers ordering within an ordering key, but it’s opt-in and comes with throughput tradeoffs. For many analytics streaming use cases, ordering doesn’t matter at the message level — you’re windowing and aggregating downstream anyway.
Consumer Model
Kafka uses a pull-based consumer group model. Consumers track offsets and can replay from any point. This makes Kafka excellent for reprocessing — you can reset a consumer group’s offset and replay a week of data.
Pub/Sub uses a push or pull subscription model. Replay is available by seeking to a timestamp, but it’s less granular than Kafka’s offset-based replay. For most ELT streaming, timestamp-based replay is sufficient.
Ecosystem and Flexibility
Kafka has a richer ecosystem: Kafka Streams, ksqlDB, Kafka Connect, and Schema Registry give you a full streaming platform. If you’re building complex event processing, enrichment, or CDC pipelines, Kafka’s ecosystem is hard to beat.
Pub/Sub integrates tightly with GCP — native connectors to Dataflow, BigQuery subscriptions, and Cloud Functions. If your stack is GCP-native, Pub/Sub pipelines are simpler to build and maintain.
My Take
For GCP-native data platforms where the primary goal is getting data into BigQuery/Bigtable, Pub/Sub is the simpler choice. For multi-cloud environments, complex event processing, or workloads requiring strict ordering and replay, Kafka is worth the operational investment.
Takeaway: There’s no universal winner. Choose based on your cloud strategy, ordering requirements, and how much operational complexity your team can absorb.
More posts
-
Apache Airflow on GCP - Patterns for Production DAGs
Production-ready patterns for Cloud Composer including DAG design, error handling, secrets management, and monitoring strategies.
-
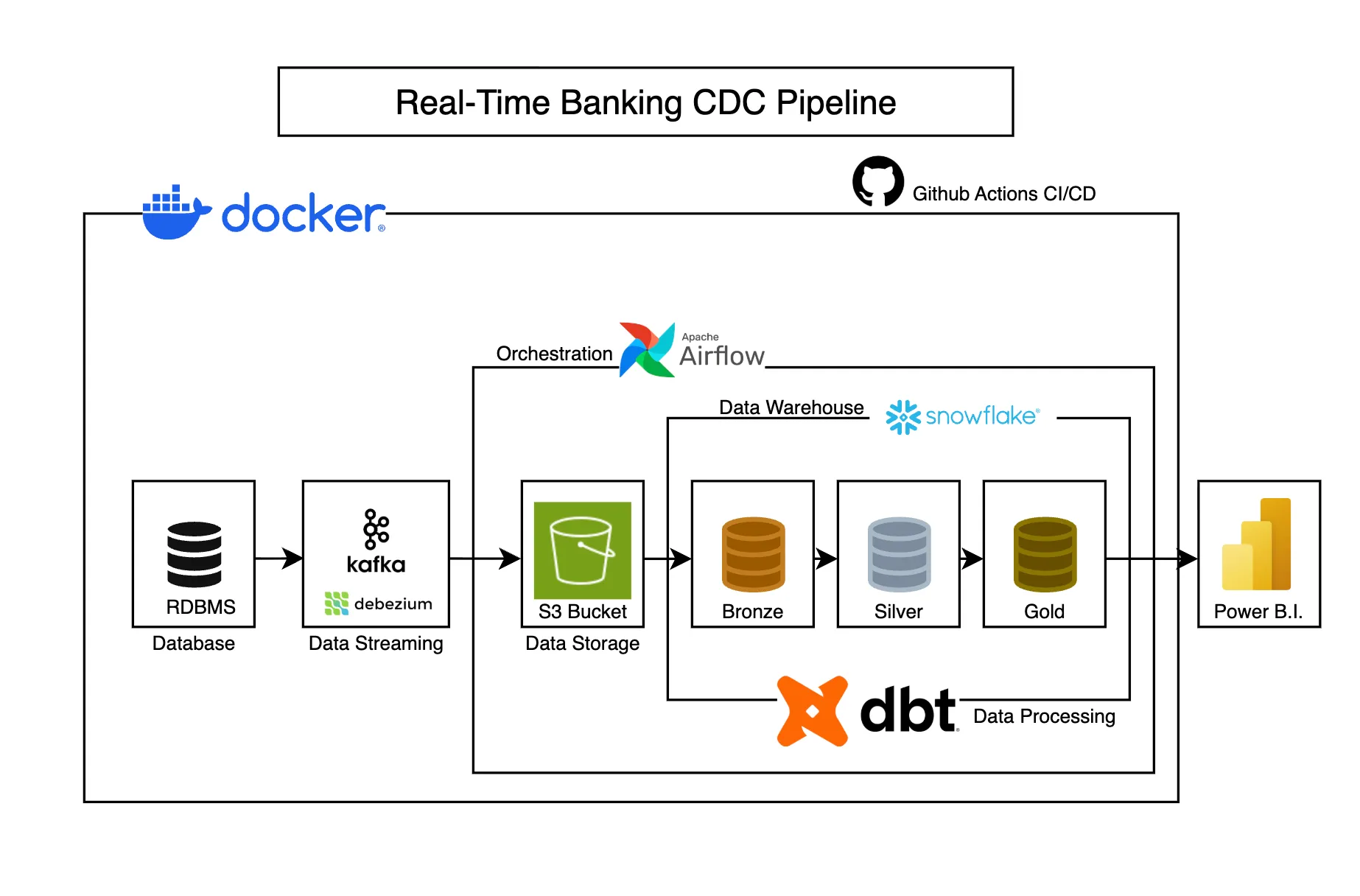
Real-Time Banking CDC Pipeline
Captures banking transaction changes in real-time using CDC, transforming operational data into analytics-ready models for business intelligence.
-
Designing a Data Lakehouse on GCP with BigLake
Unify your data lake and warehouse with BigLake. Query Parquet and ORC files in Cloud Storage directly from BigQuery with fine-grained access control.